

Покупка настенного кондиционера - это важное решение, которое обеспечит комфортное пребывание в помещении в

Московская зима не считается мягкой, и каждый год снежные покровы превращают улицы в настоящие

Брошюровка диплома – это процесс, который помогает защитить документ от повреждений и сохранить его

В мире современных технологий ноутбук - это не просто устройство, а ключ к множеству

Манипуляторы - это специализированные транспортные средства, предназначенные для поднятия и перемещения различных грузов.
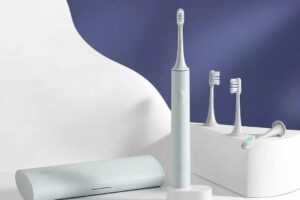
При покупке электрической зубной щетки необходимо правильно выбрать насадку для нее.

Шубы не выходят из моды уже несколько десятилетий. Они являются признаком роскоши, богатства, отличного

Для студента, школьника, делового человека ко Дню рождения, Новому году, профессиональному празднику будет уместен

Платформа All-in-One, при кажущейся экзотичности, на самом деле является вполне оправданной альтернативой ноутбукам формата


Имеется старая довольно-таки добрая и популярная пословица, с которой знаком каждый: встречают по одежке,


Даже в холодное время года представительницы прекрасного пола не хотят забывать о моде и

Совсем недавно каждой девушке необходимы были умения и навыки шитья. Однако с появлением чудесных
Пледы и покрывала являются практичными аксессуарами для домашнего использования. Такие аксессуары способны придать интерьеру

Кости говяжьи для собак являются распространенным кормом для животных, который можно использовать на протяжении

Начало учебного года, это очень важное мероприятие в жизни каждого ученика, ведь впереди целый

Квадокоптер - это небольшое устройство, которое имеет четыре пропеллера. Пропеллеры начинают своё движение

В настоящее время бумажные салфетки стали настолько неотъемлемой частью нашей повседневной жизни

Фотокамеры GoPro пользуются спросом на рынке и отличаются востребованностью, что обязательно нужно учитывать каждому


С каждым днем интернет-магазинов становится все больше, и также они набирают популярность у клиентов

Домашние животные являются важной частью жизни современного мира. При этом домашние животные требуют особого

В случае, если у владельца собственной квартиры или собственного загородного дома есть возможность,

Оригинальная шубница с крышкой отличается практичностью и удобством эксплуатации.

Сегодня, каждый покупатель мечтает о том, чтобы приобрести качественную и долговечную обувь, которая будет

Разбираемся в причинах того, почему вы хотите сменить место работы, просчитываем все риски и

